Vision Realistic DiT
v1.0

 Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image info Image info
Image infoVision Realistic Model Overview
I’m excited to introduce my latest checkpoint model, based on HunyuanDiT-v1.2. This model has been trained over 80,000 steps to ensure the generation of high-quality, photorealistic images.
Model Details :
Type: Photorealistic model
Trigger Words: None required
Chinese language support: No
Output: High-detail, high-resolution images that closely resemble real-life photographs
Configuration Used for Training:
GPU: A6000
Dataset: Combination of 5,000 stock photos and my own custom dataset
Batch Size: 2
Optimizer: AdamW
Scheduler: Cosine
Learning Rate: 1e-5
Epochs: Target of 100 epochs
Captioning: Mixed WD14 and BLIP
Training Time: 27+ hours (Experience: Bad; future training undecided)
Quick Guide and Parameters:
VAE: SDXL
Sampler: dpmpp_2m
Scheduler: sgm_uniform (Recommended for best results)
Sampling Steps: 25+
CFG Scale: 7
For better results, try using ComfyUI
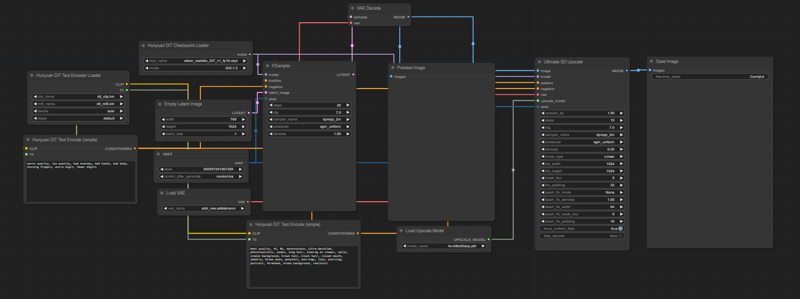
Important: Please avoid using NSFW/mature content in your prompts, as it may lead to unreliable results. Additionally, shorter prompts tend to work better with both SD3 and DiT models.
Note:
This is not a merged or modified model. It is the original Realistic Vision fine-tuned model. Some users have been spreading incorrect information in the model's comment section. If you have any questions or want to know more, join my Discord server or share your thoughts in the comment section. Thank you for your time.